 腾讯登录
腾讯登录【Nature子刊】协和医院王任直团队:自我监督对比学习在中枢神经系统疾病中的创新应用
| 导读 | 在这项研究中,团队引入了一种称为scCM的自我监督对比学习方法,用于整合大规模CNS scRNA-seq数据。 |
2024年9月10日,中国医学科学院附属北京协和医院/香港中文大学(深圳)医学院王任直团队在期刊《Communications Biology》上发表了题为“Integrating large-scale single-cell RNA sequencing in central nervous system disease using self-supervised contrastive learning”的研究论文。研究结果表明,scCM是一种稳健且有前途的整合大规模CNS scRNA-seq数据的方法,使研究人员能够深入了解CNS功能和疾病背后的细胞和分子机制。
https://www.nature.com/articles/s42003-024-06813-2
研究介绍
01
中枢神经系统(CNS)由多种细胞类型组成,每种细胞类型都具有不同的功能和基因表达谱。中枢神经系统疾病,包括缺血性、出血性、神经退行性、炎症性和发育性疾病,在CNS细胞中表现出复杂的生理或病理改变,导致功能和基因表达谱异常。由于CNS细胞可以响应各种生理和病理条件而发生异质性转化和功能变化,因此,CNS是最复杂的系统之一,包括具有独特形态和基因表达谱的多种细胞类型和亚型。
单细胞RNA测序(scRNA-seq)已成为研究与生理或病理条件相关的特定细胞类型或亚群中基因表达的关键工具。现有的scRNA-seq方法,根据其范式可分为几类:基于聚类的方(k-means、DBSCAN11、修拉12,13 元)、基于降维的方法(PCA、t-SNE、UMAP)、基于深度学习的方法 (scVI14火星15、 scGNN16)。
对比学习最近因其在计算机视觉中的自监督学习中的成功应用,而受到关注,例如,SimCLR30和MoCo31。对比学习背后的基本概念,是将相似样本映射到附近的表示空间,同时将不同的样本,映射到遥远的表示空间。scRNA-seq分析中的对比学习,旨在通过比较和对比不同的细胞或细胞亚群,来学习单细胞数据的表示。对比学习显示出克服大规模CNS scRNA-seq数据整合挑战的巨大前景。科学界已经提出了几种新颖的对比学习框架,其中,MoCoV3在各种任务上取得了最先进的性能。
在这项研究中,团队提出了scCM,这是一种用于整合大规模CNS scRNA-seq数据的自我监督对比学习模型。scCM利用最新的对比学习框架,通过比较基因表达的变异,将功能相关的CNS细胞靠在一起,同时将不同的CNS细胞分开,从而有效揭示CNS细胞类型/亚型内的异质性关系。scCM 提供了改进的性能,可以成为研究CNS细胞复杂性和异质性的宝贵工具,解决了整合大规模CNS scRNA-seq数据的重大挑战,以增强科学界对CNS功能和疾病机制的理解。
研究进展
02
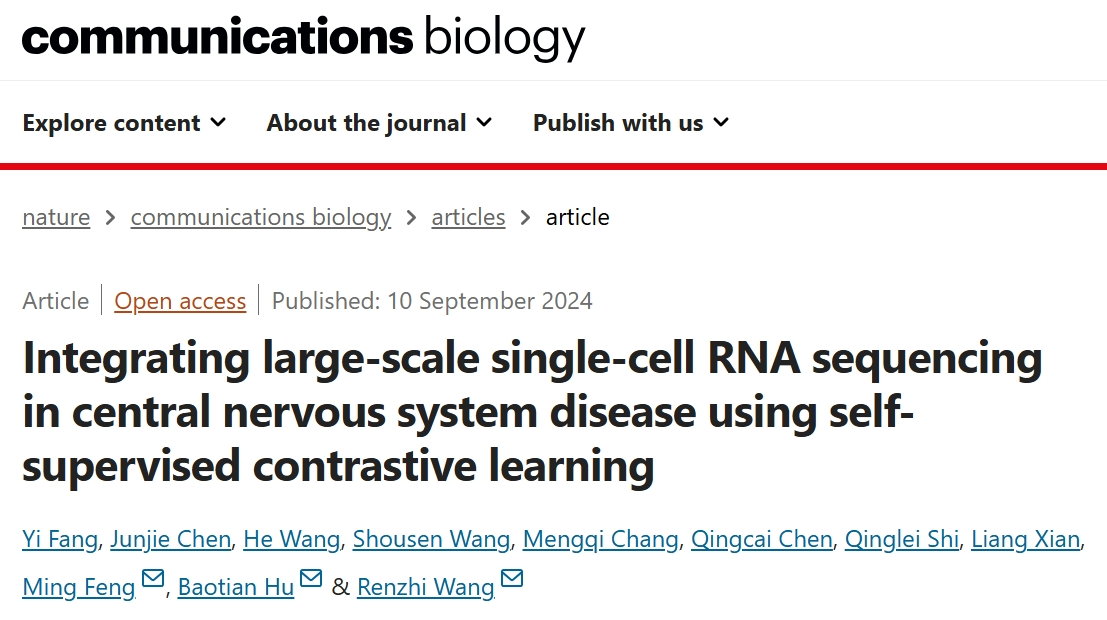
scCM在大规模CNS数据集中提供有前途的聚类分析
当使用前3,000个HVG时,scCM的性能在各种数据集中更加稳定。scCM在来自不同大陆、物种和疾病的CNS数据集上的Acc和ARI方面,具有高性能。在非神经组织数据集中,scCM也显示出良好的聚类结果。
在对具有5种脑转移类型的Gonzalez数据集的分析中,相同的癌症亚型相邻。具体来说,3种乳房亚型位于顶部,而2种卵巢亚型和3种黑色素瘤亚型,分别位于左侧和底部。然而,对于肺转移,Lung1与其他两个非小细胞肺癌集群(Lung2和Lung3)明显分开,因为Lung1是一个小细胞癌集群。此外,在Datta的数据集中,IDH突变的少突胶质细胞,通过scCM靠近胶质母细胞瘤定位。因此,scCM可以有效地表示可视化结果中的功能相似性。
团队观察到,神经免疫相关细胞倾向于聚集在右上区域,而与物质循环途径组成相关的细胞主要归类在右下区域。未知的簇和神经元细胞位于左下角区域。未知簇中的基因表达与神经损伤修复、髓鞘形成和神经递质功能有关。通过比较标记物比较,团队成功地将未知簇鉴定为嗅鞘细胞,这是一种促进轴突生长、髓鞘形成和神经营养的特殊神经胶质细胞类型。
scCM为大规模CNS数据集提供了有前途的聚类分析。
CNS细胞整合揭示细胞类型/亚型与神经退行性疾病之间的关系
由于神经退行性疾病的典型特征是神经胶质细胞的进行性异质性,因此,团队专注于一种众所周知的神经胶质细胞类型,即星形胶质细胞,它与各种神经退行性疾病有关。从参考中去除非星形胶质细胞后,星形胶质细胞在4种神经退行性疾病中分为5个亚型,具有不同的百分比。Astro 0亚型是HD的主要成分,在AD和NHD中很少见。基于高可变基因的比较,Astro 0表现出IGF2R的高表达,IGF2R是一种已知在学习和记忆等认知过程中起关键作用的基因。因此,Astro 0可用于注释HD样本。此外,Astro1和4亚型存在于所有4种神经退行性疾病中,表明它们在神经系统发育中起关键作用。然而,Astro 1是主要成分,在AD和NHD中占80%以上,表明这两种疾病在CNS细胞功能变化期间,共享基因表达谱。尽管如此,Astro 4吸收了MS中60%的成分,但其余40%由其他3种星形胶质细胞亚型组成。因此,MS中的细胞异质性,高于其他神经退行性疾病,导致MS中基因表达谱更加复杂。Astro 2和3亚型仅存在于MS样品中。根据高基因表达分析,Astro 2被确定为一种潜在的炎性星形胶质细胞,表达上调的免疫相关和细胞凋亡相关基因 (HSP、NAMPT和TPST1)。神经退行性疾病中广泛的神经元丢失归因于细胞凋亡,新出现的证据表明,细胞凋亡失调可能与MS的发病机制有关。同时,Astro 3富含与神经元发育相关的基因,尤其是纤毛功能,其中,纤毛是基于微管的微小信号装置,可调节多种生理功能。因此,MS的发展可能与星形胶质细胞亚型的异质性转化有关,炎性星形胶质细胞的出现,成为一个令人担忧的原因。此外,团队还观察到少突胶质细胞和小胶质细胞之间的异质性。
通过使用scCM,大规模CNS数据集的整合,可以促进不同CNS疾病的比较分析,从而能够探索各种生理和病理条件下的细胞异质性,并有助于全面探索CNS疾病的因果关系。
未知细胞的注释。
研究结论
03
scCM可以捕获CNS细胞中的异质性,使其能够整合大规模CNS scRNA-seq数据,以揭示基于空间关系的细胞间连接。在20个CNS数据集上的实验表明,scCM在具有不同基因、细胞、簇、物种和CNS疾病数量的数据集的聚类、处理dropout事件和校正批次效应方面,保持了出色的性能和泛化。此外,scCM可以提供CNS细胞聚集的空间可解释性,这有助于推断细胞发育或功能关系。利用scCM的这些优势,团队基于集成的大规模神经退行性数据参考,成功地注释了观察到的和未观察到的CNS细胞亚型。团队预计,该方法将在CNS领域有更广泛的应用。
有几个方向需要进一步研究:(1)scCM的评估仅对CNS scRNA-seq数据进行。需要额外的研究,来评估scCM对其他组织的适用性;(2)更大、更全面的参考数据,可以为未知细胞,提供更可靠的注释。在未来的工作中,团队计划收集更广泛的CNS数据集,以增加细胞数量,特别是关注稀有细胞亚型;(3)细胞类型和混杂因素的有限多样性,可能会降低注释的准确性。为了解决这个问题,团队计划创建一个扩展和更高质量的参考文献,专门针对不同的神经系统疾病背景量身定制;(4)分析细胞亚型,需要对每个细胞簇进行单独分析,因为它不能在一个步骤中完成。
参考资料:
1.Wang, Z. et al. Single-cell transcriptomic analyses provide insights into the cellular origins and drivers of brain metastasis from lung adenocarcinoma. Neuro Oncol. 25, 1262–1274 (2023).
2.Grubman, A. et al. A single-cell atlas of entorhinal cortex from individuals with Alzheimer’s disease reveals cell-type-specific gene expression regulation. Nat. Neurosci. 22, 2087–2097 (2019).

还没有人评论,赶快抢个沙发